
This project consists in creating a simple software tool that is able to classify and predict textual data, extrapolated from Twitter. Were considered 40183 tweet,divided between training-set (40000) and testing-set (183).
For semplicity, the tool stores the information in memory and was realized with K-NN as prediction algorithm. However it was implemented an interface “ClassificationAlgorithm” to allow any future changes to the system.
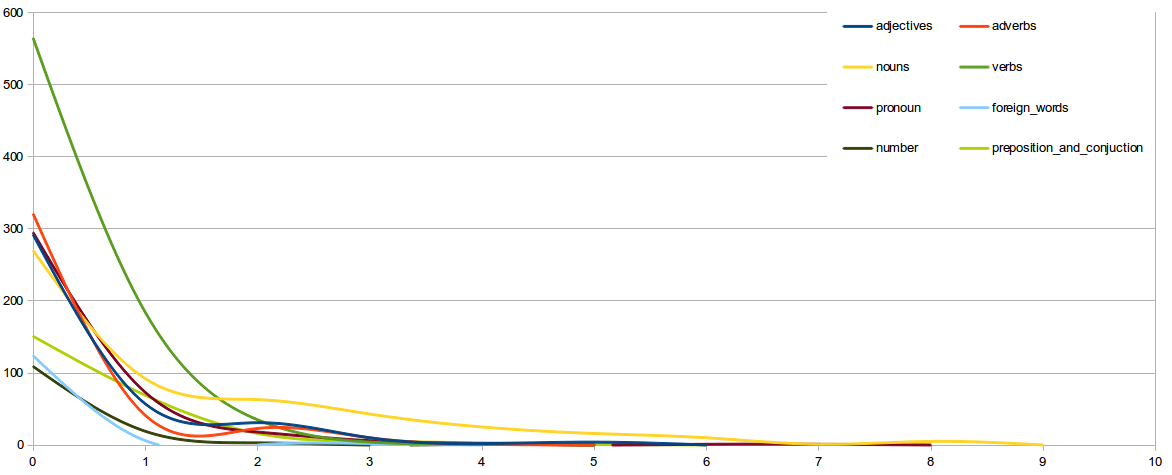
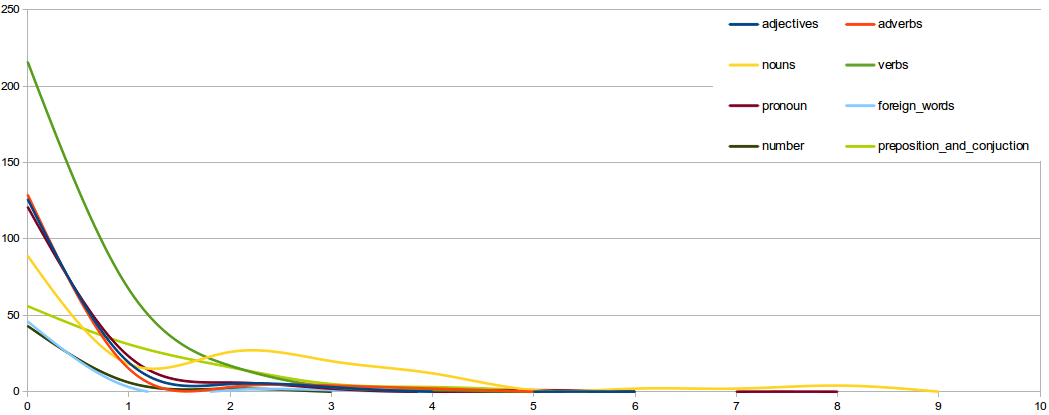
The goal of this project is to understand not only the positivity/negativity associated with a sentence, but also the influence of the parts of the speech contained therein. The tool extracts the most common measures in information retrival area, from which it was possible to extract data and charts below with a 3-NN instance.
| ConfusionMatrix | TruthPositive | TruthNegative |
| SystemPositive | 100 | 43 |
| SystemNegative | 8 | 32 |
Statistics:
- error rate: 43.04371584699454
- accuracy: 0.48
- precision: 0.6993006993006993
- recall: 0.9259259259259259
- breack-even: 0.8126133126133126
- f1-measure: 0.7968127490039841
- fails Number: 51
Positive Recap
Negative Recap
- machine learning ,
- sentiment analysis ,
- twitter ,
- java